Microbial Biotechnology services
| Name | Description | ELIXIR Node |
|---|---|---|
The microbial world provides an abundant source of biological catalysts for chemicals of medical and economic interest such as pharmaceuticals and biofuels. However, a sustainable resource for systems biology, that integrates experimental and predicted data on microbial metabolism, is still lacking. This Implementation Study defines the requirements for a European Bioinformatics resource for microbial metabolism as well as providing a practical demonstration of how existing funded resources from ELIXIR partners could be integrated to meet those needs. This Study brings together complimentary data types:
These connections via RDF standards have many underpinning implications in medicine and economy such as pharmaceuticals and biofuels. This study has now been completed, the end report is available here. An article in the ELIXIR F1000R gateway will be made available shortly. Webinar summarising the outcomes |
ELIXIR Switzerland, ELIXIR France, EMBL-EBI | |
Over the coming decade, Europe will face critical challenges in maintaining biodiversity, ensuring food security and combating pathogens. Our 2024–28 Programme will address these issues by mobilising and integrating molecular data, using successful coordination models from human genomics. Through strategic investments and collaboration in externally-funded projects, ELIXIR will enhance scientific services and support transnational research in these essential areas. The following projects have been selected as part of the ELIXIR 2024–28 Programme’s Biodiversity, food security and pathogens Science tier:
|
ELIXIR Belgium, ELIXIR France, ELIXIR Germany, ELIXIR Greece, ELIXIR Netherlands, ELIXIR Norway, ELIXIR Portugal, ELIXIR Slovenia, ELIXIR UK, EMBL-EBI, ELIXIR Italy | |
Cellular and molecular biology are fundamental to ELIXIR's mission. As part of our 2024–28 Programme, we are committed to advancing data services and software for research on nucleic acids, proteins and other biomolecules. This initiative will address new demands for multi-omics and multi-modal analyses, including imaging, by developing methods and partnerships. We will also expand expertise in reusable data and software to incorporate FAIR models, ensuring robust solutions for modelling at all scales. The following projects are key to connecting the latest developments with established data resources, unlocking the potential of cellular and molecular biology:
|
ELIXIR Belgium, ELIXIR Czech Republic, ELIXIR France, ELIXIR Greece, ELIXIR Hungary, ELIXIR Italy, ELIXIR Netherlands, ELIXIR Portugal, ELIXIR Slovenia, ELIXIR Spain, ELIXIR Sweden, ELIXIR UK, EMBL-EBI | |
Advancements in biological system engineering have introduced new data challenges in biotechnology. These challenges are even more pronounced when high-throughput robotic systems are used in screening and manufacturing. While academic projects and use cases have enabled progress in data management, industrial systems face distinct challenges related to data sharing, security, and process verification. This project aims to investigate industrial data sharing challenges. As part of the Microbial Biotechnology Community, a recent joint implementation study between Newcastle and Manchester ELIXIR Nodes explored the data management requirements of biotechnology. This effort resulted in published guidelines in collaboration with the RDMkit team (https://rdmkit.elixir-europe.org/). The study was extended to consider an automated hybrid in-vitro/in-silico workflow designed to characterise recombinant enzymes and their protein families, with a particular focus on understanding their data characteristics in an academic setting (see figure below). 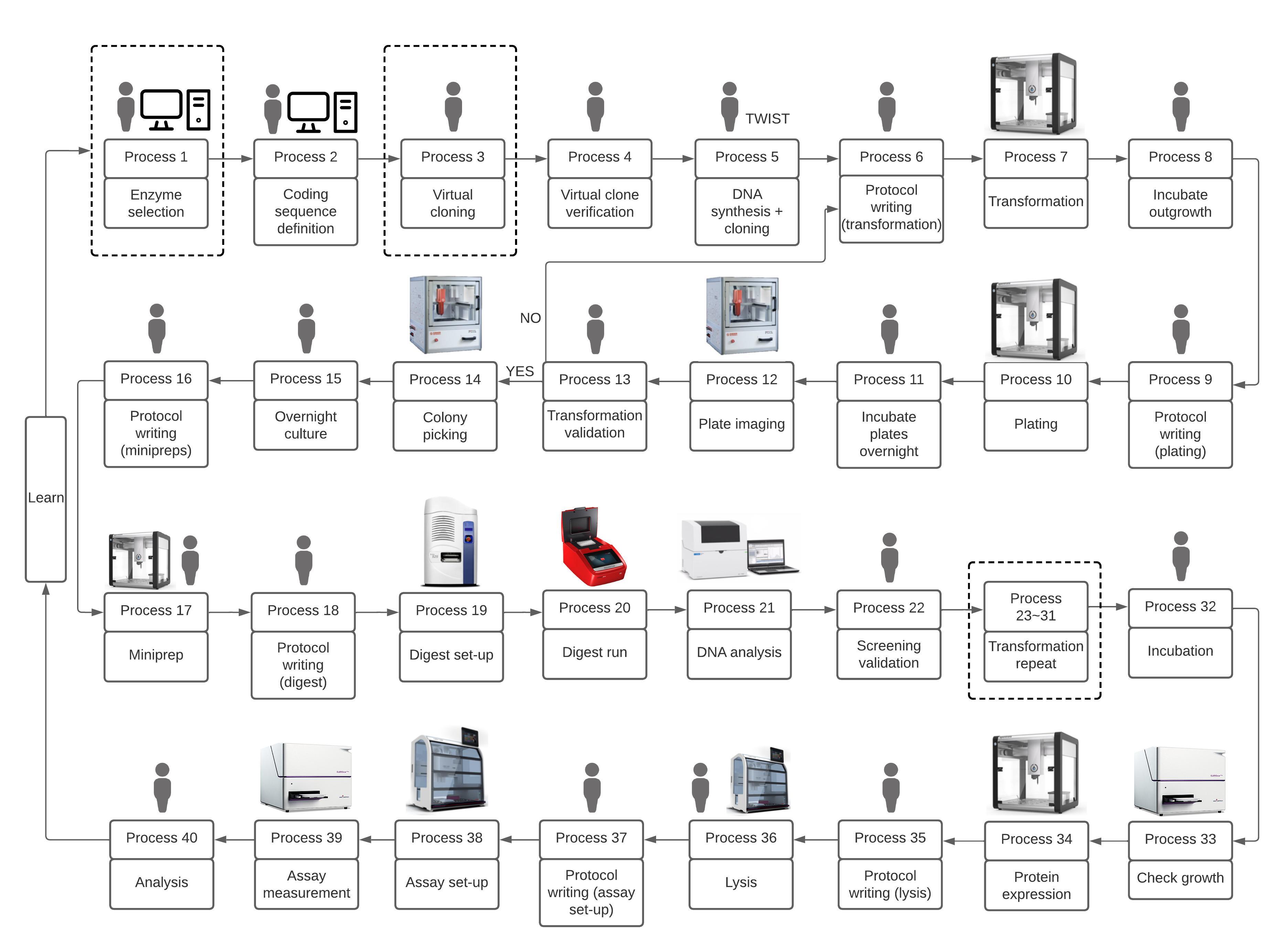 Prozomix Ltd., an SME specializing in enzyme-based biocatalysts, is using high-throughput systems to identify novel members of enzyme protein families, within the company and in collaboration with academic partners. This project proposes a technology transfer process from academia to industry, involving the adaptation and deployment of the automated pipeline at Prozomix. A data requirements analysis will address the specific data challenges faced by the industry, identifying the points at which data could be shared without undermining the company’s intellectual property. The ultimate goal is to develop generic guidelines for industrial partners to make their data FAIR (Findable, Accessible, Interoperable, and Reusable) without compromising intellectual property and data security. The project's anticipated outcomes include fostering collaboration between the ELIXIR communities and industry, encouraging academic members to explore more commercially focused use cases, and industrial members to think about FAIR data. Additionally, the project aims to highlight the differences in FAIR data needs between industry and academia and create a generic framework to facilitate data sharing in industrial biotechnology. |
ELIXIR UK | |
Advancements in biological system engineering have introduced new data challenges in biotechnology. These challenges are even more pronounced when high-throughput robotic systems are used in screening and manufacturing. While academic projects and use cases have enabled progress in data management, industrial systems face distinct challenges related to data sharing, security, and process verification. This project aims to investigate industrial data sharing challenges. As part of the Microbial Biotechnology Community, a recent joint implementation study between Newcastle and Manchester ELIXIR Nodes explored the data management requirements of biotechnology. This effort resulted in published guidelines in collaboration with the RDMkit team (https://rdmkit.elixir-europe.org/). The study was extended to consider an automated hybrid in-vitro/in-silico workflow designed to characterise recombinant enzymes and their protein families, with a particular focus on understanding their data characteristics in an academic setting (see figure below). Prozomix Ltd., an SME specializing in enzyme-based biocatalysts, is using high-throughput systems to identify novel members of enzyme protein families, within the company and in collaboration with academic partners. This project proposes a technology transfer process from academia to industry, involving the adaptation and deployment of the automated pipeline at Prozomix. A data requirements analysis will address the specific data challenges faced by the industry, identifying the points at which data could be shared without undermining the company’s intellectual property. The ultimate goal is to develop generic guidelines for industrial partners to make their data FAIR (Findable, Accessible, Interoperable, and Reusable) without compromising intellectual property and data security. The project's anticipated outcomes include fostering collaboration between the ELIXIR communities and industry, encouraging academic members to explore more commercially focused use cases, and industrial members to think about FAIR data. Additionally, the project aims to highlight the differences in FAIR data needs between industry and academia and create a generic framework to facilitate data sharing in industrial biotechnology. |
ELIXIR UK | |
This project aims to strengthen the basis for a one-stop shop connecting databases, datasets and tools for the deployment of the engineering Design-Build-Test-Learn (DBTL) framework in biotechnology. It will do so by surveying the tools and data landscape, pinpointing gaps and opportunities, and establishing design patterns for task-specific workflows for analysis, integration and sharing of multimodal data. It will provide a resource that will allow users to navigate the complex landscape of biotechnology tooling and data, as well as to establish solutions that fit their specific DBTL requirements. Use cases from ongoing programmes in various communities will be used to ascertain and establish the pragmatic value of the solutions. The work will be carried out through hands-on activities, dedicated workshops and hackathons, providing training and resources, as well as fostering industrial engagement. The experience of the communities and platforms involved in systems biology, industrial biotechnology, metabolic modelling, metabolomics, enzymes, bioprospecting and data management will be particularly valuable in this respect, as well as their respective industrial relations. Accordingly, the project engages participants from seven ELIXIR nodes and connects researchers and their activities from six communities. The project outcomes will contribute to advancing the ambition of connecting the latest developments and established data resources across ELIXIR to realise the potential of cellular and molecular biology, particularly in the fields of industrial biotechnology and biomanufacturing. |
ELIXIR Spain, ELIXIR Greece, ELIXIR France, ELIXIR Netherlands, ELIXIR Portugal, ELIXIR Slovenia, ELIXIR UK | |
| ELIXIR Belgium, ELIXIR Cyprus, ELIXIR Czech Republic, ELIXIR Denmark, ELIXIR Estonia, ELIXIR Finland, ELIXIR France, ELIXIR Germany, ELIXIR Greece, ELIXIR Hungary, ELIXIR Ireland, ELIXIR Israel, ELIXIR Italy, ELIXIR Luxembourg, ELIXIR Netherlands, ELIXIR Norway, ELIXIR Portugal, ELIXIR Slovenia, ELIXIR Spain, ELIXIR Sweden, ELIXIR Switzerland, ELIXIR UK, EMBL-EBI | ||
| ELIXIR Greece, ELIXIR Netherlands, ELIXIR Spain | ||
A formal framework for microbial biotechnology to manage and manipulate strains, samples, knowledge, data and metadata is still lacking. The Design - Build - Test - Learn (DBTL) cycle provides a conceptual framework for the development of tailor-made microbes and biological systems. The ELIXIR Microbial Community takes the DBTL cycle as a starting point for defining its four key objectives. This implementation study builds upon the F1000 position paper for the Microbial Community and will revolve around three core, closely intertwined activities: Enzymes, Models and Ontologies & Workflows. All are embedded in a Training framework and relate directly to the Platforms Data, Tools, Interoperability and Training. |
ELIXIR Netherlands, ELIXIR France, ELIXIR UK, ELIXIR Greece, ELIXIR Finland, ELIXIR Germany, ELIXIR Portugal, ELIXIR Slovenia, ELIXIR Switzerland, EMBL-EBI | |